
Building Auditable, AI-Driven Document Workflows with Foxit APIs

We had an incredible time at API World 2025 connecting with developers, sharing ideas, and seeing how Foxit APIs power everything from AI-driven resume builders to interactive doodle apps. In this post, we’ll walk through the same hands-on workflow Jorge Euceda demoed live on stage—showing how to build an auditable, AI-powered document automation system using Foxit PDF Services and Document Generation APIs.
How to Build an AI Resume Analyzer with Python & Foxit APIs (API World 25′)
This year’s API World was packed with energy—and it was amazing meeting so many developers face-to-face at the Foxit booth. We spent three days trading ideas about document automation, AI workflows, and integration challenges.
Our team hosted a hands-on workshop and sponsored the API World Hackathon, where developers submitted 16 high-quality projects built with Foxit APIs. Submissions ranged from:
Automated legal-advice generators
Compatibility-rating apps that analyze your personality match
AI-powered resume optimizers that tailor your CV to dream-job descriptions
Collaborative doodle games that turn drawings into shareable PDFs
Each project offered a new perspective on what’s possible with Foxit APIs—and we loved seeing the creativity.
Among all the sessions, Jorge Euceda’s workshop stood out as a crowd favorite. It showed how to make AI document decisions auditable, explainable, and replayable using event sourcing and two key Foxit APIs. That’s exactly what we’ll walk through below.
Replicate the Full Demo
Click here to grab the project overview file.
Prefer to follow along with the live session instead of reading step-by-step?
Watch Jorge’s complete “AI-Powered Resume to Report” presentation from API World 2025.
It includes every step shown below—plus real-time API responses.
What You’ll Build
A complete, auditable workflow:
Resume Upload → Extract Resume Data → AI Candidate Scoring → Generate HR Report → Event Store
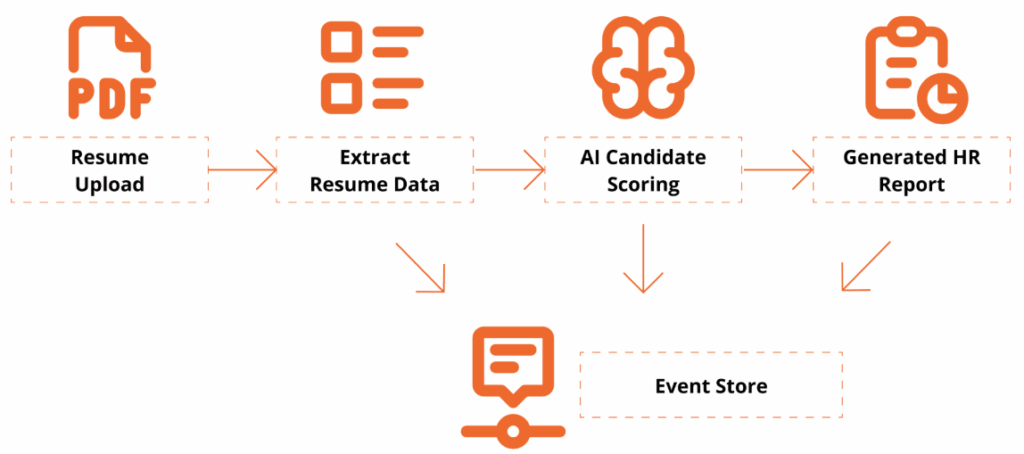
This workshop is designed for technical professionals and managers who want to learn how to use application programming interfaces (APIs) and explore how AI can enhance document workflows. Attendees will get hands-on experience with Foxit’s PDF Services (extraction/OCR) and Document Generation APIs, and see how event sourcing turns AI decisions into an auditable, replayable ledger.
By the end, you’ll have a Python-based demo that extracts data from a PDF resume, analyzes it against a policy, and generates a polished HR Report PDF with a traceable event log.
Getting Set Up
To follow along, you’ll need:
Access to a terminal with a Python 3.9+ Environment and internet connectivity
Visual Studio Code or your preferred IDE
Basic familiarity with REST/JSON (helpful but not required)
- Install Dependencies
python -V
# virtual environment setup, requests installation
python3 -m venv myenv
source myenv/bin/activate
pip3 install requests- Download the project’s zip file below
Now extract the files somewhere in your computer, open in Visual Studio Code or your preferred IDE.
You may use any sample resume PDF for inputs/input_resume.pdf. A sample one is provided, but you may leverage any resume PDF you wish to generate a report on.
- Create a Foxit Account for credentials
Create a Free Developer Account now or navigate to our getting started guide, which will go over how to create a free trial.
Hands-On Walkthrough
Step 1 – Open the Project
Now that you’ve downloaded the workshop source code, navigate to the resume_to_report.py file, which will serve as our main entry point.
Once dependencies are installed and the ZIP file extracted, open your workspace and run:
python3 resume_to_report.pyYou should see console logs showing:
An AI Report printed as JSON
A generated PDF (
outputs/HR_Report.pdf)An event ledger (
outputs/events.json) with traceable actions
Step 2 — Inspect the outputs
Open the generated HR report to review:
Candidate name and phone
Overall fit score
Matching skills & gaps
Summary and policy reference in the footer
Then open events.json to see your audit trail—each entry captures the AI’s decision context.
{
"eventType": "DecisionProposed",
"traceId": "8d1e4df6-8ac9-4f31-9b3a-841d715c2b1c",
"payload": {
"fitScore": 82,
"policyRef": "EvaluationPolicy#v1.0"
}
}This is your audit trail.
Step 3 — Replay & Explain a Policy Change
Replay demonstrates why event-sourcing matters:
Edit
inputs/evaluation_policy.json: add a hard requirement (e.g.,"kubernetes") or adjust the job_description emphasis.Re-run the script with the same resume.
Compare:
New decision and updated PDF content
Event log now reflects the updated rationale (
PolicyLoadedsnapshot → newDecisionProposedwith the sametraceIdlineage)
Emphasize: The input resume hasn’t changed; only policy did — the event ledger explains the difference.
Policy: Drive Auditable & Replayable Decisions
The AI assistant uses a JSON policy file to control how it scores, caps, and summarizes results. Every policy snapshot is logged as its own event, creating a replayable audit trail for governance and compliance.
{
"policyId": "EvaluationPolicy#v1.0",
"job_description": "Looking for a software engineer with expertise in C++, Python, and AWS cloud services. Experience building scalable applications in agile teams; familiarity with DevOps and CI/CD.",
"overall_summary": "Make the summary as short as possible",
"hard_requirements": ["C++", "python", "aws"]
}Notes:
policyIdappears in both the report and event log.job_descriptiondefines what the AI is looking for.Changing these values creates a new traceable event.
Generate a Polished Report
Next, use the Foxit Document Generation API to fill your Word template and create a formatted PDF report.
Open inputs/hr_report_template.docx, you will find the following HR reporting template with placeholders for the fields we will be entering:

Tips:
Include lightweight branding (logo/header) to make the generated PDF presentation-ready.
Include a footer with traceable Policy ID and Trace ID Events
Results and Audit Trail
Here’s what the final HR Report PDF looks like:

Every decision has a Trace ID and Policy Ref, so you can recreate the report at any time and verify how the AI arrived there.
Why Event-Sourced AI Matters
This pattern does more than score resumes—it proves that AI decisions can be transparent, deterministic, and trustworthy.
By using Foxit APIs to extract, analyze, and generate documents, developers can bring auditability to any workflow that relies on machine logic.
Key Takeaways
Auditability – Every AI step emits a verifiable event.
Replayability – Change a policy and regenerate for deterministic results.
Explainability – Decisions carry policy and trace references for clear “why.”
Automation – PDF Services and Document Generation handle the document lifecycle end-to-end.
Try It Yourself
Ready to build your own auditable AI workflow?
Demo and Source Code: document-workflows-with-foxit.pages.dev
Foxit Developer Portal: developer-api.foxit.com
API Docs: docs.developer-api.foxit.com
Watch the Full Presentation: Euceda’s API World session
Closing Thought
At API World, we set out to show how Foxit APIs can power real, transparent AI workflows—and the community response was incredible. Whether you’re building for HR, legal, finance, or creative industries, the same pattern applies:
Make your AI explain itself.
Start with the Foxit APIs, experiment with policies, and turn every AI decision into a traceable event that builds trust.
Convert Office Docs to PDFs Automatically with Foxit PDF Services API

See how to build a powerful, automated workflow that converts Office documents (Word, Excel, PowerPoint) into PDFs. This step-by-step guide uses the Foxit PDF Services API, the Pipedream low-code platform, and Dropbox to create a seamless “hands-off” document processing system. We’ll walk through every step, from triggering on a new file to uploading the final PDF.
Convert Office Docs to PDFs Automatically with Foxit PDF Services API
With our REST APIs, it is now possible for any developer to set up an integration and document workflow using their language of choice. But what about workflow automations? Luckily, this is even simpler (of course, depending on platform) as you can rely on the workflow service to handle a lot the heavy lifting of whatever automation needs you may have. In this blog post, I’m going to demonstrate a workflow making use of Pipedream. Pipedream is a low-code platform that lets you build flexible workflows by piecing together various small atomic steps. It’s been a favorite of mine for some time now, and I absolutely recommend it. But note that what I’ll be showing here today could absolutely be done on other platforms, like n8n.
Want the televised version? Catch the video below:
Our Office Document to PDF Workflow
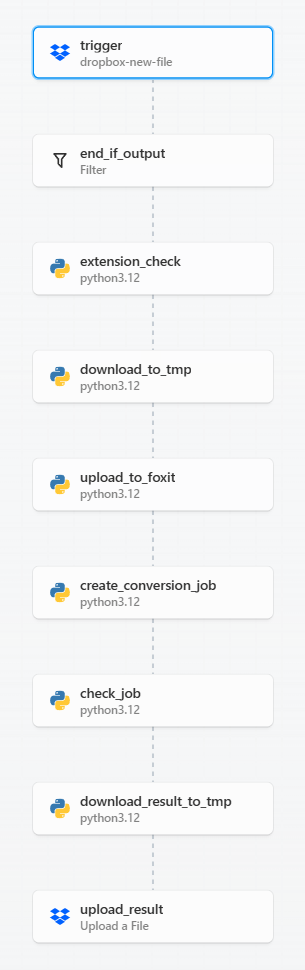
Our workflow is based on Dropbox folders and handles automatic conversion of Office docs to PDFs. To support that, it does the following:
- Listen for new files in a Dropbox folder
- Do a quick sanity check (is it in the input subdirectory and an Office file)
- Download the file to Pipedream
- Send it to Foxit via the Upload API
- Kick off the appropriate conversion based on the Office type
- Check status via the Status API
- When done, download the result to Pipedream
- And finally, push it up to Dropbox in an output subdirectory
Here’s a nice graphical representation of this workflow:
Before we get into the code, note that workflow platforms like Pipedream are incredibly flexible. When I build workflows with platforms like this I try to make each step as atomic, and focused as possible. I could absolutely have built a shorter, more compact version of this workflow. However, having it broken out like this makes it easier to copy and modify going forward (which is exactly how this one came about, it was based on a simpler, earlier version).
Ok, let's break it down, step-by-step.
Getting Triggered
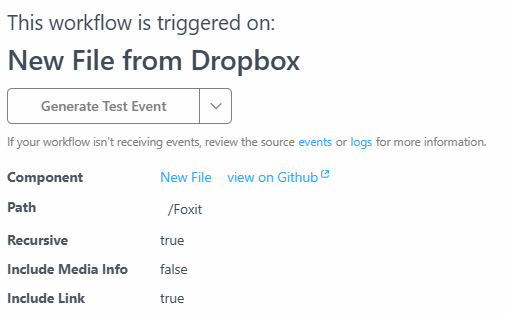
In Pipedream, workflows begin with a trigger. While there are many options for this, my workflow uses a "New File From Dropbox" trigger. I logged into Dropbox via Pipedream so it had access to my account. I then specified a top level folder, "Foxit", for the integration. Additionally, there are two more important settings:
- Recursive – this tells the trigger to file for any new file under the root directory, "Foxit". My Dropbox Foxit folder has both an input and output directory.
- Include Link – this tells Pipedream to ensure we get a link to the new file. This is required to download it later.
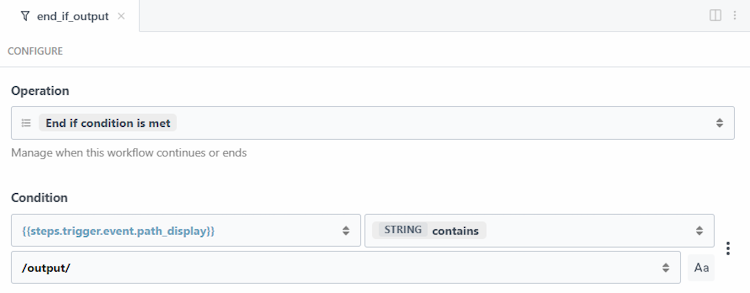
Filtering the Document Flow
The next two steps are focused on filtering and stopping the workflow, if necessary. The first, end_if_output, is a built-in Pipedream step that lets me provide a condition for the workflow to end. First, I'll check the path value from the trigger (the path of the new file) and if it contains "output", this means it's a new file in the output directory and the workflow should not run.
The next filter is a code step that handles two tasks. First, it checks whether the new file is a supported Office type—.docx, .xlsx, or .pptx—using our APIs. If the extension isn’t one of these, the workflow ends programmatically.
Later in the workflow, I’ll also need that same extension to route the request to the correct endpoint. So the code handles both: validation and preservation of the extension.
import os
def handler(pd: "pipedream"):
base, extension = os.path.splitext(pd.steps['trigger']['event']['name'])
if extension == ".docx":
api = "/pdf-services/api/documents/create/pdf-from-word"
elif extension == ".xlsx":
api = "/pdf-services/api/documents/create/pdf-from-excel"
elif extension == ".pptx":
api = "/pdf-services/api/documents/create/pdf-from-ppt"
else:
return pd.flow.exit(f"Exiting workflow due to unknow extension: {extension}.")
return { "api":api }As you can see, if the extension isn't valid, I'm exiting the workflow using pd.flow.exit (while also logging out a proper message, which I can check later via the Pipedream UI). I also return the right endpoint if a supported extension was used. This will be useful later in the flow.
Download and Upload API Data
The next two steps are primarily about moving data from the input source (Dropbox) to our API (Foxit).
The first step, download_to_tmp, uses a simple Python script to transfer the Dropbox file into the /tmp directory for use in the workflow
import requests
def handler(pd: "pipedream"):
download_url = pd.steps["trigger"]["event"]["link"]
file_path = f"/tmp/{pd.steps['trigger']['event']['name']}"
with requests.get(download_url, stream=True) as response:
response.raise_for_status()
with open(file_path, "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
return file_pathNotice at the end that I return the path I used in Pipedream. This action then leads directly into the next step of uploading to Foxit via the Upload API:
import os
import requests
def handler(pd: "pipedream"):
clientid = os.environ.get('FOXIT_CLIENT_ID')
secret = os.environ.get('FOXIT_CLIENT_SECRET')
HOST = os.environ.get('FOXIT_HOST')
headers = {
"client_id":clientid,
"client_secret":secret
}
with open(pd.steps['download_to_tmp']['$return_value'], 'rb') as f:
files = {'file': (pd.steps['download_to_tmp']['$return_value'], f)}
request = requests.post(f"{HOST}/pdf-services/api/documents/upload", files=files, headers=headers)
return request.json()The result of this will be a documentId value that looks like so:
{
"documentId": "<string>"
}Pipedream lets you define environment variables and I've made use of them for my Foxit credentials and host. Grab your own free credentials here!
Converting the Document Using the Foxit API
The next step will actually kick off the conversion. My workflow supports three different input types (Word, PowerPoint, and Excel). These map to three API endpoints. But remember that earlier we sniffed the extension of our input and set the endpoint there. Since all three APIs work the same, that's literally all we need to do – hit the endpoint and pass the document value from the previous step.
import os
import requests
def handler(pd: "pipedream"):
clientid = os.environ.get('FOXIT_CLIENT_ID')
secret = os.environ.get('FOXIT_CLIENT_SECRET')
HOST = os.environ.get('FOXIT_HOST')
headers = {
"client_id":clientid,
"client_secret":secret,
"Content-Type":"application/json"
}
body = {
"documentId": pd.steps['upload_to_foxit']['$return_value']['documentId']
}
api = pd.steps['extension_check']['$return_value']['api']
print(f"{HOST}{api}")
request = requests.post(f"{HOST}{api}", json=body, headers=headers)
return request.json(){
"taskId": "<string>"
}
Checking Your Document API Status
The next step is one that may take a few seconds – checking the job status. Foxit's endpoint returns a value like so:
{
"taskId": "<string>",
"status": "<string>",
"progress": "<int32>",
"resultDocumentId": "<string>",
"error": {
"code": "<string>",
"message": "<string>"
}
}import os
import requests
from time import sleep
def handler(pd: "pipedream"):
clientid = os.environ.get('FOXIT_CLIENT_ID')
secret = os.environ.get('FOXIT_CLIENT_SECRET')
HOST = os.environ.get('FOXIT_HOST')
headers = {
"client_id":clientid,
"client_secret":secret,
"Content-Type":"application/json"
}
done = False
while done is False:
request = requests.get(f"{HOST}/pdf-services/api/tasks/{pd.steps['create_conversion_job']['$return_value']['taskId']}", headers=headers)
status = request.json()
if status["status"] == "COMPLETED":
done = True
return status
elif status["status"] == "FAILED":
print("Failure. Here is the last status:")
print(status)
return pd.flow.exit("Failure in job")
else:
print(f"Current status, {status['status']}, percentage: {status['progress']}")
sleep(5)As shown, errors are simply logged by default—but you could enhance this by adding notifications, such as emailing an admin, sending a text message, or other alerts.
On success, the final output is passed along, including the key value we care about: resultDocumentId.
Download and Upload – Again
Ok, if the workflow has gotten this far, it's time to finish the process. The next step handles downloading the result from Foxit using the download endpoint:
import requests
import os
def handler(pd: "pipedream"):
clientid = os.environ.get('FOXIT_CLIENT_ID')
secret = os.environ.get('FOXIT_CLIENT_SECRET')
HOST = os.environ.get('FOXIT_HOST')
headers = {
"client_id":clientid,
"client_secret":secret,
}
# Given a file of input.docx, we need to use input.pdf
base_name, _ = os.path.splitext(pd.steps['trigger']['event']['name'])
path = f"/tmp/{base_name}.pdf"
print(path)
with open(path, "wb") as output:
bits = requests.get(f"{HOST}/pdf-services/api/documents/{pd.steps['check_job']['$return_value']['resultDocumentId']}/download", stream=True, headers=headers).content
output.write(bits)
return {
"filename":f"{base_name}.pdf",
"path":path
}Note that I'm using the base name of the input, which is basically the filename minus the extension. So for example, input.docx will become input, which I then slap a pdf extension on to create the filename used to store locally to Pipedream.
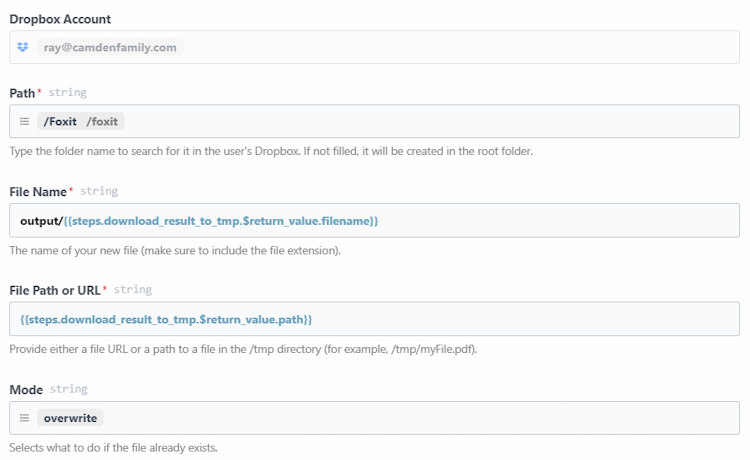
Finally, I push the file back up to Dropbox, but for this, I can use a built-in Pipedream step that can upload to Dropbox. Here's how I configured it:
- Path: Once again,
Foxit - File Name: This one's a bit more complex, I want to store the value in the output subdirectory, and ensure the filename is dynamic. Pipedream lets you mix and match hard-coded values and expressions. I used this to enable that:
output/{{steps.download_result_to_tmp.$return_value.filename}}. In this expression the portion inside the double bracket will be dynamic based on the PDF file generated previously. - File Path: This is an expression as well, pointing to where I saved the file previously:
{{steps.download_result_to_tmp.$return_value.path}} - Mode: Finally, the mode attribute specifies what to do on a conflict. This setting will be based on whatever your particular workflow needs are, but for my workflow, I simply told Dropbox to overwrite the existing file.
Here's how that step looks configured in Pipedream:
Conclusion
Believe it or not, that's the entire workflow. Once enabled, it runs in the back ground and I can simply place any files into my Dropbox folder and my Office docs will be automatically converted. What's next? Definitely get your own free credentials and check out the docs to get started. If you run into any trouble at all, hit is up on the forums and we'll be glad to help!
Generate Dynamic PDFs from JSON using Foxit APIs

See how easy it is to generate PDFs from JSON using Foxit’s Document Generation API. With Word as your template engine, you can dynamically build invoices, offer letters, and agreements—no complex setup required. This tutorial walks through the full process in Python and highlights the flexibility of token-based document creation.
Generate Dynamic PDFs from JSON using Foxit APIs
One of the more fascinating APIs in our library is the Document Generation API. This document generation API lets you create dynamic PDFs or Word documents using your own data as templates. That may sound simple – and the code you’re about to see is indeed simple – but the real power lies in how flexible Word can be as a template engine. This API could be used for:
- Creating invoices
- Creating offer letters
- Creating dynamic agreements (which can integrate with our eSign API)
All of this is made available via a simple API and a “token language” you’ll use within Word to create your templates. Let’s take a look at how this is done.
Credentials
Before we go any further, head over to our developer portal and grab a set of free credentials. This will include a client ID and secret values – you’ll need both to make use of the API.
Don’t want to read all of this? You can also follow along by video:
Using the API
The Document Generation API flow is a bit different from our PDF Services APIs in that the execution is synchronous. You don’t need to upload your document beforehand or download a result result. You simply call the API (passing your data and template) and the result has your new PDF (or Word document). With it being this simple, let’s get into the code.
Loading Credentials
My script begins by loading in the credentials and API root host via the environment:
CLIENT_ID = os.environ.get('CLIENT_ID')
CLIENT_SECRET = os.environ.get('CLIENT_SECRET')
HOST = os.environ.get('HOST')As always, try to avoid hard coding credentials directly into your code.
Calling the API
The endpoint only requires you to pass the output format, your data, and a base64 version of your file. “Your data” can be almost anything you like—though it should start as an object (i.e., a dictionary in Python with key/value pairs). Beneath that, anything goes: strings, numbers, arrays of objects, and so on.
Here’s a Python wrapper showing this in action:
def docGen(doc, data, id, secret):
headers = {
"client_id":id,
"client_secret":secret
}
body = {
"outputFormat":"pdf",
"documentValues": data,
"base64FileString":doc
}
request = requests.post(f"{HOST}/document-generation/api/GenerateDocumentBase64", json=body, headers=headers)
return request.json()And here’s an example calling it:
with open('../../inputfiles/docgen_sample.docx', 'rb') as file:
bd = file.read()
b64 = base64.b64encode(bd).decode('utf-8')
data = {
"name":"Raymond Camden",
"food": "sushi",
"favoriteMovie": "Star Wars",
"cats": [
{"name":"Elise", "gender":"female", "age":14 },
{"name":"Luna", "gender":"female", "age":13 },
{"name":"Crackers", "gender":"male", "age":13 },
{"name":"Gracie", "gender":"female", "age":12 },
{"name":"Pig", "gender":"female", "age":10 },
{"name":"Zelda", "gender":"female", "age":2 },
{"name":"Wednesday", "gender":"female", "age":1 },
],
}
result = docGen(b64, data, CLIENT_ID, CLIENT_SECRET)You’ll note here that my data is hard-coded. In a real application, this would typically be dynamic—read from the file system, queried from a database, or sourced from any other location.
The result object contains a message representing the success or failure of the operation, the file extension for the result, and the base64 representation of the result. Most likely you’ll always be outputting PDFs, so here’s a simple bit of code that stores the result:
with open('../../output/docgen1.pdf', 'wb') as file:
file.write(binary_data)
print('Done and stored to ../../output/docgen1.pdf')There’s a bit more to the API than I’ve shown here so be sure to check the docs, but now it’s time for the real star of this API, Word
Using Word as a Template
I’ve probably used Microsoft Word for longer than you’ve been alive and I’ve never really thought much about it. But when you begin to think of a simple Word document as a template, all of a sudden the possibilities begin to excite you. In our Document Generation API, the template system works via simple “tokens” in your document marked by opening and closing double brackets.
Consider this block of text:
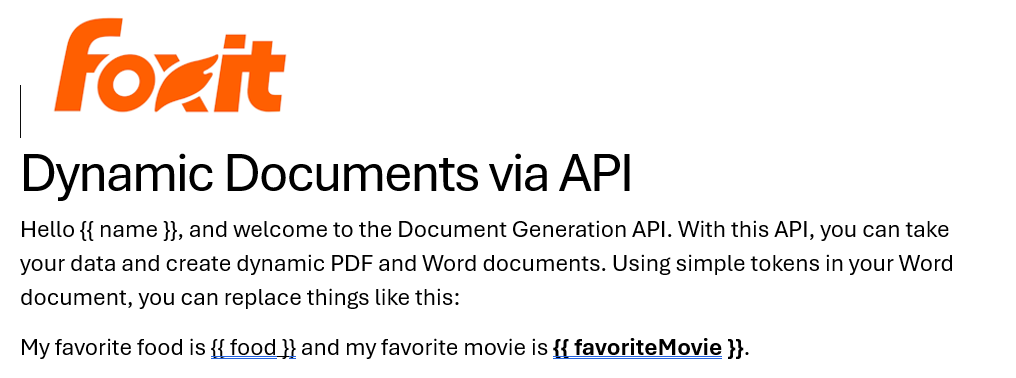
See how name is surrounded by double brackets? And food and favoriteMovie? When this template is sent to the API along with the corresponding values, those tokens are replaced dynamically. In the screenshot, notice how favoriteMovie is bolded. That’s fine. You can use any formatting, styling, or layout options you wish.
That’s one example, but you also get some built-in values as well. For example, including today as a token will insert the current date, and can be paired with date formatting to specify how the date looks:
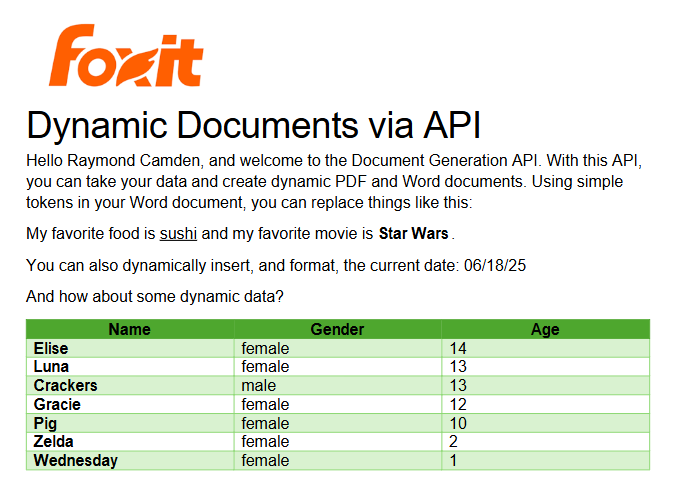
Remember the array of cats from earlier? You can use that to create a table in Word like this:

Notice that I’ve used two new tags here, TableStart and TableEnd, both of which reference the array, cats. Then in my table cells, I refer to the values from that array. Again, the color you see here is completely arbitrary and was me making use of the entirety of my Word design skills.
Here’s the template as a whole to show you everything in context:

The Result
Given the code shown above with those values, and given the Word template just shared, once passed to the API, the following PDF is created:
Ready to Try?
If this looks cool, be sure to check the docs for more information about the template language and API. Sign up for some free developer credentials and reach out on our developer forums with any questions.
Want the code? Get it on GitHub.
If you are more of a Node person, check out that version. Get it on GitHub.
Introducing PDF APIs from Foxit

Get started with Foxit’s new PDF APIs—convert Word to PDF, generate documents, and embed files using simple, scalable REST APIs. Includes sample Python code and walkthrough.
Introducing PDF APIs from Foxit
At the end of June, Foxit introduced a brand-new suite of tools to help developers work with documents. These APIs cover a wide range of features, including:
- Convert between Office document formats and PDF files seamlessly
- Optimize, manipulate, and secure PDFs with advanced APIs
- Generate dynamic documents using Microsoft Word templates
- Extract text and images from PDFs with powerful tools
- Embed PDFs into web pages in a context-aware, controlled manner
- Integrate with eSign APIs for streamlined signature workflows
These APIs are simple to use, and best of all, follow the “don’t surprise me” principal of development. In this post, I’m going to demonstrate one simple example – converting a Word document to PDF – but you can rest assured that nearly all the APIs will follow incredibly similar patterns. I’ll be using Python for my examples here, but will link to a Node.js version of the same example. And given that we’re talking REST APIs here, any language is welcome to join the document party. Let’s dive in.
Credentials
Before we go any further, head over to our developer portal and grab a set of free credentials. This will include a client ID and secret values you’ll need to make use of the API.
Don’t want to read all of this? You can also follow along by video:
API Flow
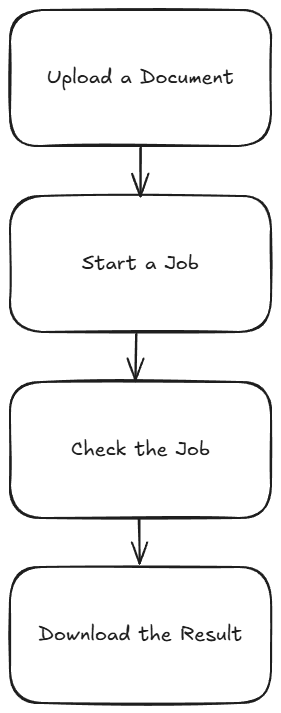
As I mentioned above, most of the PDF Services APIs will follow a similar flow. This comes down to:
- Upload your input (like a Word document)
- Kick off a job (like converting to PDF)
- Check the job (hey, how ya doin?)
- Download the result
Or, in pretty graphical format –
The great thing is, once you’ve completed one integration (this post focuses on converting Word to PDF), switching to another is easy—and much of your existing code can be reused. A lazy developer is happy developer! Let’s get started.
Loading Credentials
My script begins by loading the credentials and API root host via the environment:
CLIENT_ID = os.environ.get('CLIENT_ID')
CLIENT_SECRET = os.environ.get('CLIENT_SECRET')
HOST = os.environ.get('HOST')It’s never a good idea to hard-code credentials in your code. But if you do it this one time, I won’t tell. Honest.
Uploading Your Input
As I mentioned, in this example we’ll be making use of the Word to PDF API. Our input will be a Word document, which we’ll upload to Foxit using the upload API. This endpoint is fairly simple – aside from your credentials, all you need to provide is the binary data of the input file. Here’s the method I created to make this process easier:
def uploadDoc(path, id, secret):
headers = {
"client_id":id,
"client_secret":secret
}
with open(path, 'rb') as f:
files = {'file': (path, f)}
request = requests.post(f"{HOST}/pdf-services/api/documents/upload", files=files, headers=headers)
return request.json()And here’s how it’s used:
doc = uploadDoc("../../inputfiles/input.docx", CLIENT_ID, CLIENT_SECRET)
print(f"Uploaded doc to Foxit, id is {doc['documentId']}")The upload API only returns one value, a documentId, which we can use in future calls.
Starting the Job
Each API operation is a job creator. By this I mean you call the endpoint and it begins your action. For Word to PDF, the only required input is the document ID from the previous call. We can build a nice little wrapper function like so:
def convertToPDF(doc, id, secret):
headers = {
"client_id":id,
"client_secret":secret,
"Content-Type":"application/json"
}
body = {
"documentId":doc
}
request = requests.post(f"{HOST}/pdf-services/api/documents/create/pdf-from-word", json=body, headers=headers)
return request.json()And then call it like so:
task = convertToPDF(doc["documentId"], CLIENT_ID, CLIENT_SECRET)
print(f"Created task, id is {task['taskId']}")The result of this call, if no errors were found, isa taskId. We can use this to gauge how the job’s performing. Let’s do that now.
Job Checking
Ok, so the next part can be a bit tricky depending on your language of choice. We need to use the task status endpoint to determine how the job is performing. How often we do this, how quickly and so forth, will depend on your platform and needs. For our little sample script here, everything is running at once. I wrote a function that will check the status. If the job isn’t finished (whether successful or not), it pauses briefly before trying again. While this approach isn’t the most sophisticated, it should work well enough for basic testing:
def checkTask(task, id, secret):
headers = {
"client_id":id,
"client_secret":secret,
"Content-Type":"application/json"
}
done = False
while done is False:
request = requests.get(f"{HOST}/pdf-services/api/tasks/{task}", headers=headers)
status = request.json()
if status["status"] == "COMPLETED":
done = True
# really only need resultDocumentId, will address later
return status
elif status["status"] == "FAILED":
print("Failure. Here is the last status:")
print(status)
sys.exit()
else:
print(f"Current status, {status['status']}, percentage: {status['progress']}")
sleep(5)As you can see, I’m using a while loop that—at least in theory—will continue running until a success or failure response is returned, with a five-second pause between each call. You can adjust that interval as needed—test different values to see what works best for your use case. Typically, most API calls should complete in under ten seconds, so a five-second delay felt like a reasonable default.
Each call to the endpoint returns a task status result. Here’s an example:
{
'taskId': '685abc95a0d113558e4204d7',
'status': 'COMPLETED',
'progress': 100,
'resultDocumentId': '685abc952475582770d6917b'
}The important part here is the status. But you could also use progress to give some feedback to the code waiting for results. Here’s my code calling this:
result = checkTask(task["taskId"], CLIENT_ID, CLIENT_SECRET)
print(f"Final result: {result}")Downloading Your Result
The last piece of the puzzle is simply saving the result. If you noticed above, the task returned a resultDocumentId value. Taking that, and the [Download Document](NEED LINK) endpoint, we can build a utility to store the result like so:
def downloadResult(doc, path, id, secret):
headers = {
"client_id":id,
"client_secret":secret
}
with open(path, "wb") as output:
bits = requests.get(f"{HOST}/pdf-services/api/documents/{doc}/download", stream=True, headers=headers).content
output.write(bits)And finally, call it:
downloadResult(result["resultDocumentId"], "../../output/input.pdf", CLIENT_ID, CLIENT_SECRET)
print("Done and saved to: ../../output/input.pdf")And that’s it! While this script could certainly benefit from more robust error handling, it demonstrates the basic flow. As mentioned, most of our APIs follow this same logic.
Next Steps
Want the complete scripts? Get it on GitHub.
Want it in Node.js? Get it on GitHub.
Rather try this yourself? Sign up for a free developer account now. Need help? Head over to our developer forums and post your questions and comments.