How to Extract Text from PDFs using Foxit’s REST APIs
PDFs are an excellent way to store information—they combine text, images, and more in a perfectly laid-out, eye-catching design that fulfills every marketer’s wildest dreams. But sometimes you just need the text! There’s a variety of reasons you may want to convert a rich PDF document into plain text:
- For indexing in a search engine
- To search documents for keywords
- To pass to generative AI services for introspection
Let’s take a look at the Extract API to see just how easy this is.
Start Here: Obtain Free Credentials to Use the Foxit API
Before we go any further, head over to our developer portal and grab a set of free credentials. This will include a client ID and secret values – you’ll need both to make use of the API.
Rather watch the movie version? Check out the video below:
Foxit PDF API Workflow Overview with Python
The API follows the same format as the rest of our PDF Services in that you upload your input, kick off the job, check the job’s status, and download the result. As we’ve covered this a few times now on the blog (see my introductory post, we’ll skip over the details of uploading the document and loading in credentials. Here’s the Python code we’ve demonstrated before showing this in action:
CLIENT_ID = os.environ.get('CLIENT_ID')
CLIENT_SECRET = os.environ.get('CLIENT_SECRET')
HOST = os.environ.get('HOST')
def uploadDoc(path, id, secret):
headers = {
"client_id":id,
"client_secret":secret
}
with open(path, 'rb') as f:
files = {'file': (path, f)}
request = requests.post(f"{HOST}/pdf-services/api/documents/upload", files=files, headers=headers)
return request.json()
doc = uploadDoc("../../inputfiles/input.pdf", CLIENT_ID, CLIENT_SECRET)
print(f"Uploaded pdf to Foxit, id is {doc['documentId']}")Now let's get into the meat of the Extract API. The API takes three arguments:
- The ID of the previously uploaded document.
- The type of information to extract—either TEXT, IMAGE, or PAGE. In theory, it should be pretty obvious what these do, but just in case: TEXT returns the text contents of the PDF. IMAGE gives you a ZIP file of images from the PDF. PAGE returns a new PDF containing just the page you requested.
- You can also pass in a page range, which can be a combo of specific pages and ranges. If you don’t include one, the entire PDF gets processed for extraction.
To make this simple to use, I've built a wrapper function that lets you pass these arguments:
def extractPDF(doc, type, id, secret, pageRange=None):
headers = {
"client_id":id,
"client_secret":secret,
"Content-Type":"application/json"
}
body = {
"documentId":doc,
"extractType":type
}
if pageRange:
body["pageRange"] = pageRange
request = requests.post(f"{HOST}/pdf-services/api/documents/modify/pdf-extract", json=body, headers=headers)
return request.json()Literally, that's it. At this point, you get a task object back that – like with our other APIs – can be checked for completion, and once it’s done, the results can be downloaded. Since we're working with text, though, let's simplify and just grab the text as a variable:
def getResult(doc, id, secret):
headers = {
"client_id":id,
"client_secret":secret
}
return requests.get(f"{HOST}/pdf-services/api/documents/{doc}/download", headers=headers).textdoc = uploadDoc("../../inputfiles/input.pdf", CLIENT_ID, CLIENT_SECRET)
print(f"Uploaded pdf to Foxit, id is {doc['documentId']}")
task = extractPDF(doc["documentId"], "TEXT", CLIENT_ID, CLIENT_SECRET)
print(f"Created task, id is {task['taskId']}")
result = checkTask(task["taskId"], CLIENT_ID, CLIENT_SECRET)
print(f"Final result: {result}")
text = getResult(result["resultDocumentId"], CLIENT_ID, CLIENT_SECRET)
print(text)Searching PDFs for Keywords
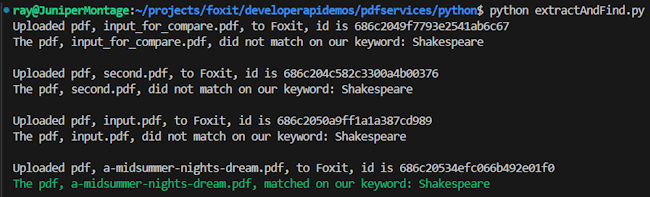
# Get PDFs from our input directory
inputFiles = list(filter(lambda x: x.endswith('.pdf'), os.listdir('../../inputfiles')))
# Keyword to match on:
keyword = "Shakespeare"
for file in inputFiles:
doc = uploadDoc(f"../../inputfiles/{file}", CLIENT_ID, CLIENT_SECRET)
print(f"Uploaded pdf, {file}, to Foxit, id is {doc['documentId']}")
task = extractPDF(doc["documentId"], "TEXT", CLIENT_ID, CLIENT_SECRET)
result = checkTask(task["taskId"], CLIENT_ID, CLIENT_SECRET)
text = getResult(result["resultDocumentId"], CLIENT_ID, CLIENT_SECRET)
if keyword in text:
print(f"\033[32mThe pdf, {file}, matched on our keyword: {keyword}\033[0m")
else:
print(f"The pdf, {file}, did not match on our keyword: {keyword}")
print("")