
Document Generation Explained: How the Template-to-API Pipeline Actually Works
Manual document workflows break down fast as volume grows. This guide explains what document generation is, how template-driven APIs replace manual processes, and what the pipeline looks like from a Word template and JSON payload to a finished PDF.
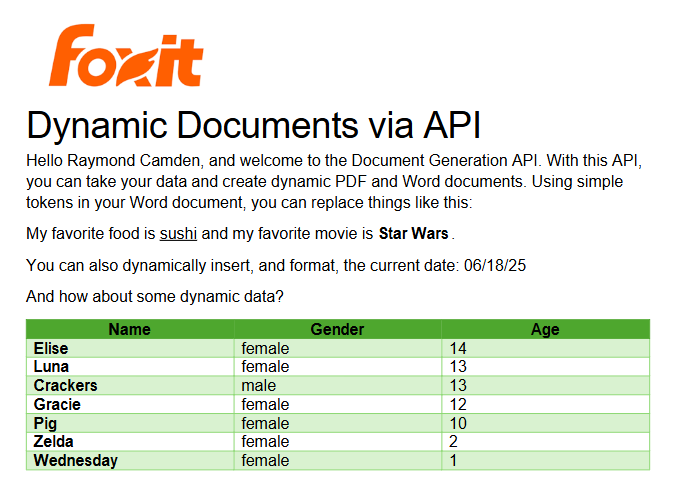
The rendering engine walks the template, matches each token to the corresponding key in the payload, and writes the formatted value into the output. Template authors work entirely in Word, while the engine handles token resolution, format application, and output assembly.
Repeating sections use loop delimiters to produce table rows that repeat for each element in a JSON array. Placing {{TableStart:lineItems}} before a table row and {{TableEnd:lineItems}} after it tells the engine to emit one row per object in the lineItems array. Both delimiters must sit in cells of the same Word table row. Inside that loop, {{ROW_NUMBER}} auto-increments across rows, and a footer row immediately below the loop can use {{=SUM(ABOVE) \# "$#,##0.00"}} to compute and format a column total, so a ten-line invoice produces a correctly numbered, fully summed table with no post-processing.
Conditional content uses Word’s native Field Code View (opened with ALT + F9) to write IF-field conditions that show or hide text blocks based on data values. A clause that should appear only when contractType equals "enterprise" lives inside a field condition, and the rendering engine evaluates it at generation time. There’s no separate scripting layer and no custom expression language to learn.
The three components converge at a single API endpoint: your base64-encoded DOCX template and JSON data payload go in together, and the generated document comes back in the same HTTP response.

The API Pipeline: From POST Request to Final Document
The Foxit DocGen API compresses the generation pipeline into a single synchronous call. You POST to one endpoint with your template and data, and you receive the generated document in the same HTTP response, with no separate template upload step, no job ID to poll, and no webhook to configure for individual document generation.
Before building a generation workflow, you can use the Analyze Document API to scan a DOCX template and return a list of all embedded tokens, which confirms the token-to-key mapping before you commit to a data schema. That’s a single POST to a separate endpoint on the same host, and it returns a structured list of placeholder names and their types.
For the generation call itself, the dev-tier endpoint is:
POST https://na1.fusion.foxit.com/document-generation/api/GenerateDocumentBase64
Authentication passes your client_id and client_secret as custom HTTP headers alongside Content-Type: application/json. You retrieve both credentials from the dashboard at account.foxit.com/site/sign-up after activating your free developer plan, with no OAuth exchange and no session setup required before your first call.
The request body takes three fields:
base64FileStringis your DOCX template, base64-encoded. Keep the source.docxunder 4 MB (the practical ceiling for a single request) since base64 encoding inflates the payload by roughly 33%. If a template runs large, embedded images are usually the cause, so compress them through Word’s Picture Format settings before exporting.documentValuesis the JSON object whose keys map to token names in the templateoutputFormatis the string"pdf"or"docx", lowercase and exact (the API returns HTTP 500 for any other value, including"PDF"or"DOCX")
For an invoice template with a lineItems array, the full curl command carries your base64-encoded DOCX, the matching data object, and your credentials in the request headers:
Automate Dynamic PDF Generation with the Foxit DocGen API: Word Templates, JSON Data, and Real API Calls
Skip the HTML-to-PDF headaches. Use Foxit’s DocGen API to turn Word templates and JSON data into clean, formatted PDFs with one API call.
Foxit DocGen API Quickstart: Word Template to Pixel-Perfect PDF in Under 10 Minutes

Go from a Word template to a pixel-perfect PDF in under 10 minutes with the Foxit DocGen API. This guide covers template authoring, JSON payload structure, the GenerateDocumentBase64 call, and the most common errors that trip people up.
Most document generation quickstarts hand you a template with one text field, a trivial JSON payload, and no explanation of what breaks when you add a repeating table, a date format string, or a missing key. You end up in the docs trying to work backwards from a 400 error. This tutorial covers the complete Foxit DocGen API flow end-to-end: authoring a Word template with scalar fields, formatted dates, and repeating line-item rows; building the matching JSON payload; and POSTing everything to GenerateDocumentBase64 to retrieve a production-ready PDF. Working Python and cURL throughout.
Before starting, you’ll need a free Foxit developer account at developer-api.foxit.com (no credit card required; the free tier includes 500 credits/year), your client_id and client_secret from the developer dashboard, Python 3.x with requests installed (pip install requests), and Microsoft Word for template authoring.
How the Foxit DocGen API Works: One Endpoint, One Call
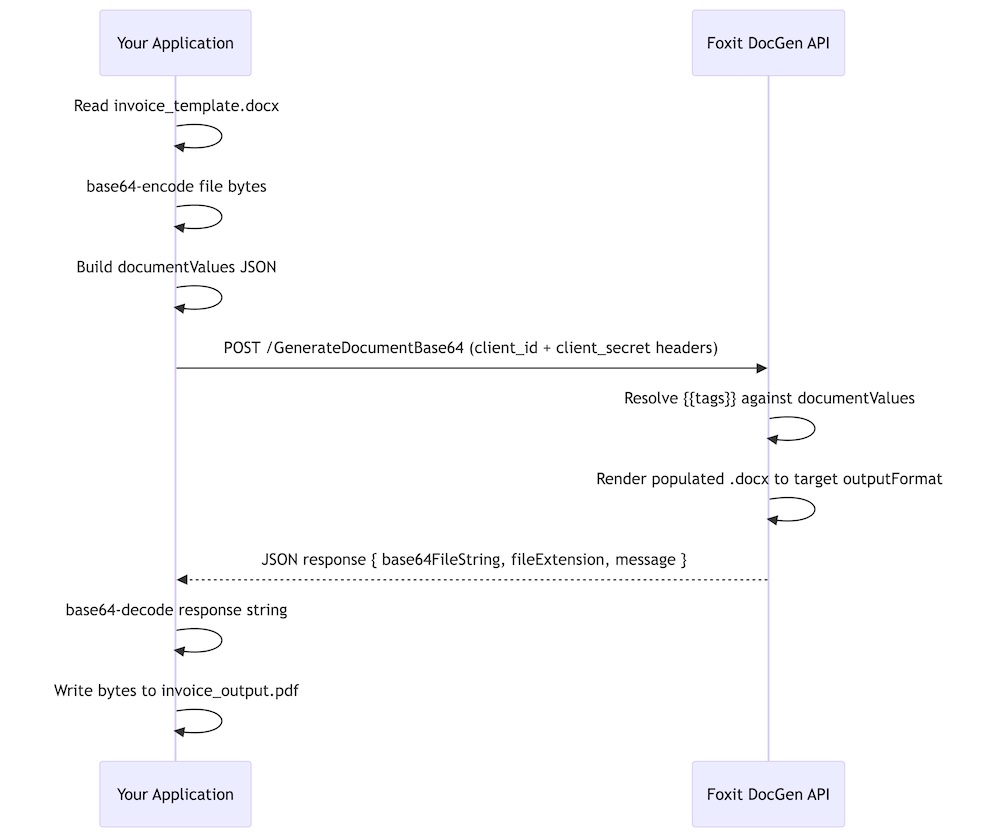
The GenerateDocumentBase64 endpoint accepts a single POST request and returns the rendered document in the same response body. You pass three things: your .docx template (base64-encoded), your structured JSON data, and the desired output format. The API merges template with data and returns the rendered file as a base64-encoded string.
Your .docx file defines layout, branding, and placeholder tokens. Your JSON payload carries the runtime values that populate those tokens. The API resolves every token in the template against the corresponding key in documentValues and renders the result as a PDF or DOCX.
 The call is synchronous, returning the rendered file in the HTTP 200 response body with no job ID, polling loop, or webhook callback required. The request body always carries three keys:
The call is synchronous, returning the rendered file in the HTTP 200 response body with no job ID, polling loop, or webhook callback required. The request body always carries three keys: base64FileString (your .docx template, base64-encoded), documentValues (the JSON object whose keys map to template tokens), and outputFormat ("pdf" or "docx").
Authentication passes client_id and client_secret as custom HTTP headers on every request, with no OAuth 2.0 flow and no token exchange step.
Author Your Word Template with Dynamic Tags
Open Word and create a standard .docx. Place your dynamic content using double-curly-brace tokens typed directly in the document body.
For scalar string and number fields, the syntax is {{field_name}}. For a date with a specific display pattern, use {{ field_name \@ MM/dd/yyyy }}. The \@ format string controls how the API renders date values from your JSON payload.
An invoice template header section looks like this:
Generate Dynamic PDFs from JSON using Foxit APIs

See how easy it is to generate PDFs from JSON using Foxit’s Document Generation API. With Word as your template engine, you can dynamically build invoices, offer letters, and agreements—no complex setup required. This tutorial walks through the full process in Python and highlights the flexibility of token-based document creation.


Document Generation API: Automate Personalized Document Creation at Scale
Automate document creation at scale with a document generation API. Learn how templates and JSON data replace manual workflows to produce PDFs instantly.
Somewhere in your company right now, someone is copying client data from a CRM into a Word document, updating the logo, adjusting the date, and exporting it to PDF. If you’re lucky, it’s an intern doing this for 50 documents a month. If you’re not, it’s a developer who hard-coded the layout in iText or PDFKit, and Marketing is about to ask them to change the font size.
Neither of those is a document generation strategy. They’re workarounds, and like legacy Mail Merge tools that choke on anything beyond a few hundred records, they don’t scale to 50,000 invoices overnight.
The good news is that the problem is well-solved. A document generation API lets you treat documents exactly like you treat any other data pipeline. A template defines the structure, a JSON payload carries the content, and the API outputs a polished, production-ready PDF (or DOCX) in milliseconds. The copy-paste step disappears entirely.
This guide walks through how that works, where it fits in real-world systems, and how tools like Foxit’s DocGen API make the implementation straightforward, even for a team that’s never touched a document automation system before.
What Is a Document Generation API?
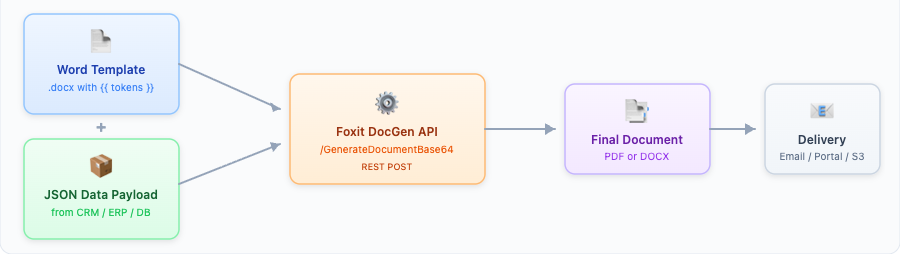
A document generation API is a cloud service that merges a template with structured data to produce a final document, typically a PDF or DOCX. The template defines layout, fonts, branding, and placeholder tokens. A JSON payload supplies the dynamic values. The API engine renders the finished document in milliseconds, with no manual intervention and no layout code required.
The equation looks like this:
Template (Structure) + JSON Data (Content) + API Engine = Final Document
Using a document generation API rather than building a local generator offers two key advantages, scalability and separation of concerns.
On the scalability side, the same POST request that generates one invoice generates 100,000 invoices. You don’t need to provision more rendering capacity, manage memory pressure from large PDFs, or debug pagination edge cases. The API handles all of that. On the separation-of-concerns side, your legal team can update a liability clause in the Word template without touching your codebase. Your marketing team can swap the logo without a redeploy. The document’s design is fully decoupled from the application logic that drives it.
That said, not all document generation tools take the same approach. Older solutions like PDFKit or Apache PDFBox require you to code the visual layout programmatically by drawing lines, positioning text boxes, and calculating column widths manually. That works for simple, static documents. It breaks down fast when tables grow dynamically, when conditional sections appear based on customer data, or when stakeholders want to iterate on the design. The API approach flips that model. The design stays in the template while the logic stays in the API.
The Architecture of Document Generation Automation
Understanding the three-layer architecture makes every implementation decision easier. Here’s how the pieces fit together.
1. Template Creation
With a modern document generation API like Foxit’s, you don’t write rendering code. You open Microsoft Word, design the document exactly as it should look, and insert double-bracket tokens wherever dynamic data belongs.
To skip ahead and inspect a working artifact, two ready-made templates accompany this tutorial. The scalar-only version (invoice_simple.docx) is geared toward your first end-to-end run, and the full version (invoice_table.docx) adds the line-items table loop and a SUM(ABOVE) subtotal. Both live in the companion Foxit demo templates repo. Open them in Word to see the placeholder syntax in context, then copy the patterns into your own template.
A simple invoice template might include:
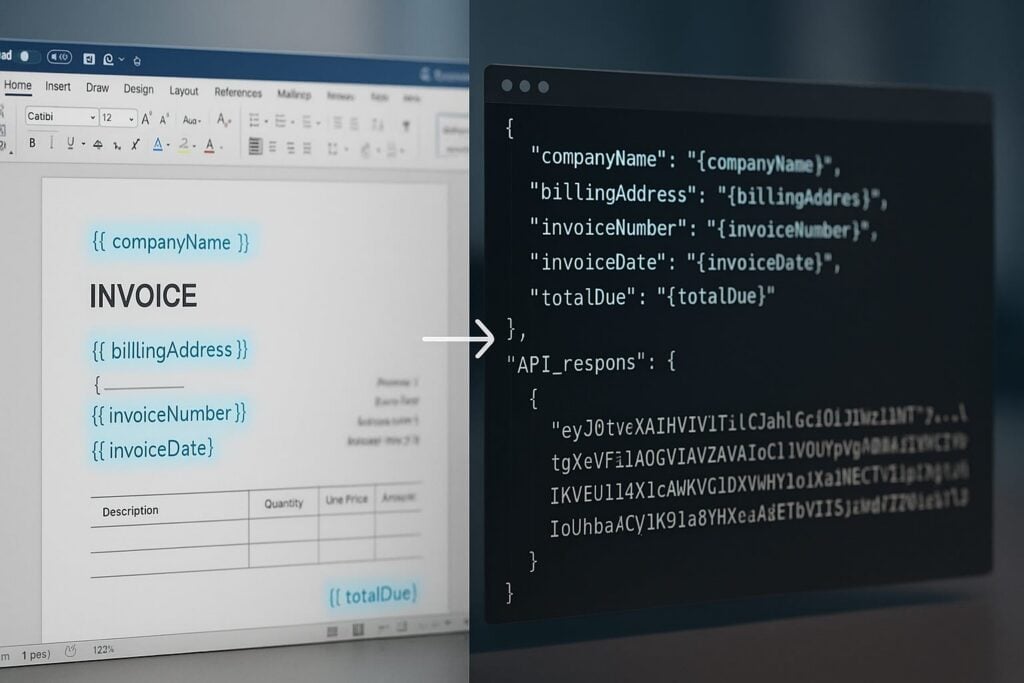
{{ companyName }}is replaced with the client’s company name{{ invoiceNumber }}is replaced with a string likeINV-00471{{ invoiceDate \@ MM/dd/yyyy }}is replaced with a date formatted as01/15/2024{{ totalDue \# "$#,##0.00" }}is replaced with a currency-formatted number like$2,500.00
That’s it. Business users can open this .docx file, update the header font, move the logo, or reword a clause, and none of those changes require a developer.
2. Data Binding
Your application pulls data from wherever it lives (a Salesforce CRM, an SAP ERP, a PostgreSQL database) and structures it as a JSON payload. The JSON keys map directly to the template token names. No transformation layer, no intermediate format.
A payload for the invoice above looks like:
Building Auditable, AI-Driven Document Workflows with Foxit APIs

We had an incredible time at API World 2025 connecting with developers, sharing ideas, and seeing how Foxit APIs power everything from AI-driven resume builders to interactive doodle apps. In this post, we’ll walk through the same hands-on workflow Jorge Euceda demoed live on stage—showing how to build an auditable, AI-powered document automation system using Foxit PDF Services and Document Generation APIs.


Create Custom Invoices with Word Templates and Foxit Document Generation

Invoicing is a critical part of any business. This tutorial shows how to automate the process by creating dynamic, custom PDF invoices with the Foxit Document Generation API. Learn how to design a Microsoft Word template with special tokens, prepare your data in JSON, and then use a simple Python script to generate your final invoices.

