Somewhere in your company right now, someone is copying client data from a CRM into a Word document, updating the logo, adjusting the date, and exporting it to PDF. If you’re lucky, it’s an intern doing this for 50 documents a month. If you’re not, it’s a developer who hard-coded the layout in iText or PDFKit, and Marketing is about to ask them to change the font size.
Neither of those is a document generation strategy. They’re workarounds, and like legacy Mail Merge tools that choke on anything beyond a few hundred records, they don’t scale to 50,000 invoices overnight.
The good news is that the problem is well-solved. A document generation API lets you treat documents exactly like you treat any other data pipeline. A template defines the structure, a JSON payload carries the content, and the API outputs a polished, production-ready PDF (or DOCX) in milliseconds. The copy-paste step disappears entirely.
This guide walks through how that works, where it fits in real-world systems, and how tools like Foxit’s DocGen API make the implementation straightforward, even for a team that’s never touched a document automation system before.
What Is a Document Generation API?
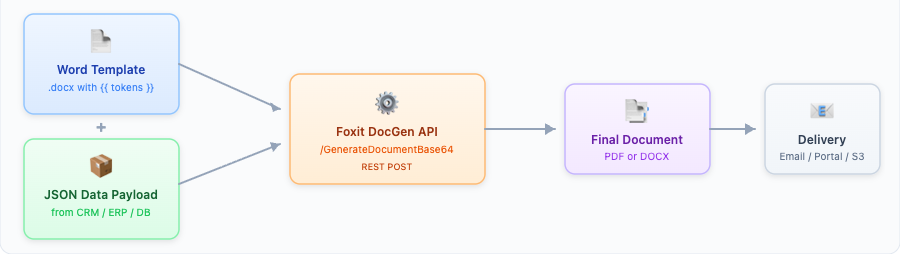
A document generation API is a cloud service that merges a template with structured data to produce a final document, typically a PDF or DOCX. The template defines layout, fonts, branding, and placeholder tokens. A JSON payload supplies the dynamic values. The API engine renders the finished document in milliseconds, with no manual intervention and no layout code required.
The equation looks like this:
Template (Structure) + JSON Data (Content) + API Engine = Final Document
Using a document generation API rather than building a local generator offers two key advantages, scalability and separation of concerns.
On the scalability side, the same POST request that generates one invoice generates 100,000 invoices. You don’t need to provision more rendering capacity, manage memory pressure from large PDFs, or debug pagination edge cases. The API handles all of that. On the separation-of-concerns side, your legal team can update a liability clause in the Word template without touching your codebase. Your marketing team can swap the logo without a redeploy. The document’s design is fully decoupled from the application logic that drives it.
That said, not all document generation tools take the same approach. Older solutions like PDFKit or Apache PDFBox require you to code the visual layout programmatically by drawing lines, positioning text boxes, and calculating column widths manually. That works for simple, static documents. It breaks down fast when tables grow dynamically, when conditional sections appear based on customer data, or when stakeholders want to iterate on the design. The API approach flips that model. The design stays in the template while the logic stays in the API.
The Architecture of Document Generation Automation
Understanding the three-layer architecture makes every implementation decision easier. Here’s how the pieces fit together.
1. Template Creation
With a modern document generation API like Foxit’s, you don’t write rendering code. You open Microsoft Word, design the document exactly as it should look, and insert double-bracket tokens wherever dynamic data belongs.
To skip ahead and inspect a working artifact, two ready-made templates accompany this tutorial. The scalar-only version (invoice_simple.docx) is geared toward your first end-to-end run, and the full version (invoice_table.docx) adds the line-items table loop and a SUM(ABOVE) subtotal. Both live in the companion Foxit demo templates repo. Open them in Word to see the placeholder syntax in context, then copy the patterns into your own template.
A simple invoice template might include:
{{ companyName }}is replaced with the client’s company name{{ invoiceNumber }}is replaced with a string likeINV-00471{{ invoiceDate \@ MM/dd/yyyy }}is replaced with a date formatted as01/15/2024{{ totalDue \# "$#,##0.00" }}is replaced with a currency-formatted number like$2,500.00
That’s it. Business users can open this .docx file, update the header font, move the logo, or reword a clause, and none of those changes require a developer.
2. Data Binding
Your application pulls data from wherever it lives (a Salesforce CRM, an SAP ERP, a PostgreSQL database) and structures it as a JSON payload. The JSON keys map directly to the template token names. No transformation layer, no intermediate format.
A payload for the invoice above looks like: