Most machine translation tools give you a translated file and nothing else. They do not tell you which parts are correct and which parts are wrong. For a simple blog post, that is fine. For a contract, a medical form, or a legal notice, it is a real problem. A bad translation can sit in the final PDF for days before anyone notices, often only after the document has already been signed or sent.
Teams today are translating more documents, into more languages, and faster than ever. Legal, finance, healthcare, HR, and insurance teams all deal with PDFs where one wrong word can cause a lot of damage: a broken contract, a failed audit, or even a safety issue. Most translation tools were not built to catch these mistakes. They just move text from one language to another. When quality checks happen at all, they usually mean a person reading the final PDF line by line and hoping they spot the errors.
This article shows how to build a better setup. You will learn how to build a PDF translation pipeline that gives every segment a quality score before the final PDF is created. Instead of hoping the translation is right, the pipeline tells you which parts to trust, which parts to review, and which parts to send back to a human translator. All of this happens automatically on every run.
Architecture at a Glance
Before going deeper, it helps to see the full pipeline in one picture. The diagram below traces a source PDF through every stage: extract, translate, score, route, and render. Each box is a single responsibility handled by a single service, with the routing layer acting as the glue you control.

The pipeline has two external services:
- Foxit PDF Translation API handles anything PDF-specific. It pulls the structured text out of the source document with element IDs attached, then renders the final PDF back in the original layout (multi-column text, tables, font substitution, image positions) using the approved translations.
- Straker AI translates each source segment AND scores the translation in the same request. It returns the target text, a numeric score on a 0.0 to 1.0 scale, and a categorical label (
best,good,acceptable,bad) for every element ID. This step is pluggable, so you can swap Straker for DeepL, Google Cloud Translation, AWS Translate, or an in-house NMT if you already have a contract with one of them. The contract between this step and the rest of the pipeline is a flat dict of element IDs to translated text plus per-segment scores.
and one piece of code you own:
- Routing layer is your business logic. It reads the score, decides whether the segment auto-accepts, flags for human review, or escalates to a translator, and then hands the approved set to Foxit’s render call.
With the shape of the pipeline on the table, the rest of the article works through each piece in order, starting with why per-segment quality scoring is worth the integration effort in the first place.
The Quality Gap
You ship a translated PDF to a legal team. Three days later, compliance flags a clause in the German version. The term “indemnification” was rendered as “Entschädigung” (compensation) rather than “Freistellung” (hold harmless). Your MT pipeline returned a 200 status. Nobody’s alerting on that delta.
Raw machine translation output carries no quality signal by default. Every segment comes back translated, and your pipeline treats them identically regardless of whether the model was confident or guessing. For marketing copy that’s an acceptable tradeoff, but for a loan covenant, a clinical trial protocol, or a regulatory filing, a 95%-accurate translation can still be contractually or legally dangerous because the 5% failure may concentrate precisely in the high-stakes clauses.
A confidence score, in the translation QA context, is a per-segment numeric signal from a verification engine. It tells you how reliable each translated unit is on a scale your system can act on programmatically. High-confidence segments auto-accept, medium-confidence ones queue for post-edit review, and low-confidence segments escalate directly to a human translator before they ever reach the final document.
The compound problem for PDFs specifically is that most translation pipelines strip document structure before the MT engine even sees the text. The extraction step flattens multi-column layouts, collapses table cells, and drops font metadata. By the time you get a translated output, you’ve lost both layout fidelity and any quality signal. The rendered PDF looks wrong and you have no programmatic way to know which segments caused it.
Foxit’s PDF Translation Trial API extracts structured text from a source PDF with element IDs preserved, so the layout blueprint travels alongside the text through the entire workflow. You hand the source segments to Straker AI, which returns the translated text plus a per-segment numeric score and a quality label in a single call. (If you already run DeepL, Google Cloud Translation, AWS Translate, or an in-house NMT Engine, you can drop it in at this step without changing the rest of the pipeline.) Your routing logic decides which segments pass, which get flagged, and which escalate to human review. Foxit’s render endpoint then re-assembles the PDF in the original layout using the accepted translations, giving you a layout-preserved translated PDF with a documentable quality trail attached to every segment.
How the Pipeline Works
Foxit and Straker are two independent APIs that you wire together. Foxit owns PDF structure, extracting structured text keyed by element ID and re-rendering the final PDF in the original layout. Straker AI handles translation and per-segment quality scoring in a single request, returning the translated text alongside a numeric score and a quality label. You own the routing decision that sits between the scores and the render call.
The pipeline runs in seven steps:
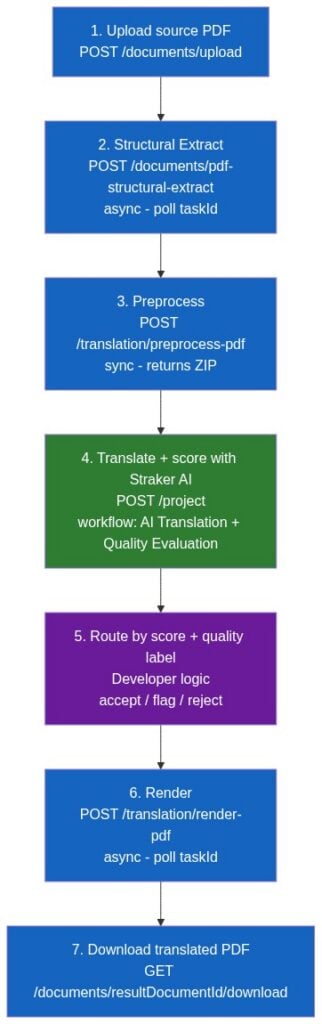
Foxit covers steps 1-3 and 6-7 (PDF structure and rendering). Straker AI covers step 4, producing translations and per-segment quality scores in one round-trip. Step 5 is your business logic.
The Foxit PDF Translation API defines steps 2, 3, and 6. The upload and download calls use the general PDF Services endpoints. Straker AI is a separate API at https://api-verify.straker.ai. You submit XLF 1.2 files containing source segments and Straker returns the translated target_text per segment plus a numeric score (0.0 to 1.0) and a quality label (best, good, acceptable, bad). Because Foxit’s ExtractedText.json is a flat { "elementId": "text" } map, and XLF trans-unit IDs round-trip through Straker’s external_id field unchanged, the element IDs Foxit emits are the same IDs that come back with translations and scores attached. That alignment is what makes programmatic routing possible.
One clarification for readers who’ve seen the Foxit-Straker partnership announcement: that partnership covers Foxit eSignature Services, enabling end users to translate and sign documents in the eSign product. That’s an end-user feature. The PDF Translation Trial API used here is a separate developer surface. Its OpenAPI spec (v2.2.0) contains zero Straker references, and the preprocess-pdf documentation explicitly instructs developers to “translate the text in ExtractedText.json using your preferred translation tool.” You wire the two APIs together manually. This tutorial uses Straker AI as the default translation engine because it produces translations and quality scores in the same call, but you can substitute DeepL, Google Cloud Translation, AWS Translate, or your own NMT at step 4 without changing the Foxit calls.
Credentials and Setup
Get your Foxit credentials at app.developer-api.foxit.com/pricing. The free Developer plan gives you 20 AI credits per month with no credit card and no sales call required. Once you’ve signed in, your Client ID and Client Secret appear in the developer dashboard. Every Foxit API call requires both in the request headers as client_id and client_secret (lowercase snake_case). Export them in your shell as FOXIT_CLIENT_ID and FOXIT_CLIENT_SECRET so the code below reads them from the environment rather than hard-coding secrets.
For Straker, sign up at straker.ai/ai-platform/verify for API access. Straker issues a UUID-style API token that you send as a bearer token on every call (Authorization: Bearer <your-token>). The API lives at https://api-verify.straker.ai and its full reference is published at api-verify.straker.ai/docs. Export your token as STRAKER_API_KEY for the code below. You can confirm the token works and check your balance with a quick GET /user/balance. Both services offer trial access, so you can build and test the full pipeline before any procurement conversation.
Before you finalize your language matrix, check both APIs for supported languages. Foxit’s render endpoint accepts 23 target language codes (en, zh, zh_tw, fr, de, es, it, pt, nl, ja, ko, th, vi, hi, ru, ar, tr, pl, sv, no, nb, da, and fi). Straker AI identifies languages by UUID rather than ISO code. You fetch the full list with GET /languages and look up the UUID for your target (for example, 917FF728-0725-A033-1278-33025F49CA40 is French (France), 917FF7D8-9107-0BF8-97EE-065C20F453DE is German). The intersection of the two sets determines your production language coverage.
If you already have a contract with DeepL, Google Cloud Translation, AWS Translate, or an in-house NMT service, you can swap that engine in at step 4. The pipeline contract upstream (Foxit element IDs mapped to source strings) and downstream (a dict of {element_id: {score, quality, target_text}} feeding the router) does not change. The code below uses Straker AI by default because the same API returns the translation and the quality signal in one call.
Building the PDF Translation Pipeline
The complete seven-step pipeline runs in Python using requests, json, zipfile, os, and the standard-library xml.etree.ElementTree for building XLF. The first snippet covers Foxit steps 1-3 (upload, structural extraction, and preprocessing).