

Your PDF extraction pipeline passes unit tests against the sample invoices you built it on. Then production arrives and you’re looking at 47% garbled output on the Q4 contract batch because half those documents are scanned TIFFs wrapped in a PDF envelope, and your extraction library has no concept of what an image-only page actually is.
The failure modes are specific. PyMuPDF’s get_text() returns empty strings on scanned PDFs because it reads content streams directly, and image-only pages carry no text stream. pdfplumber’s table detection merges rows when column widths span non-uniform grids, which is standard in any financial statement that mixes summary and line-item rows on the same page. Embedded images containing meaningful text (stamped signatures, engineering drawing annotations, letterhead logos) get silently dropped. The library extracts coordinates for the XObject reference but does nothing with the raster data inside. Form fields built on non-standard annotation types (AcroForms using widget annotations with custom action streams) lose their values entirely when you serialize to text.
The architectural distinction that creates this problem is the difference between content serialization and semantic extraction. A PDF converter reads a content stream and writes out whatever character sequences it finds in rendering order. An extraction engine understands the spatial relationships between those character sequences: that two columns of text at x=72 and x=320 are parallel body copy, that the row at y=210 belongs to the table starting at y=180, that the text block repeating on every page is a header carrying lower retrieval weight in a RAG index. Output that lacks spatial and semantic classification looks correct on screen but breaks every downstream consumer that depends on structure.
BI dashboards require numbers tied to the right row labels. AI ingestion pipelines require heading hierarchy to chunk accurately. CRMs require form field values extracted from AcroForm widget dictionaries, delivered with field names intact. The delta between what basic extraction libraries return and what those systems can actually consume is where document pipeline engineering hours accumulate.
How Foxit’s PDF Structural Extraction Engine Works Under the Hood
Foxit exposes this capability as the PDF Structural Extraction (Trial) endpoint inside the PDF Services API (POST /pdf-services/api/documents/pdf-structural-extract). Trial status means the schema is versioned at v1.0.7 and may evolve, but the contract is stable enough to build against today, and the endpoint runs against the production base URL at developer-api.foxit.com.
The engine runs three coordinated layers. The OCR layer operates on rasterized page content, recognizing characters from image-based PDFs and scanned documents across 200+ languages. The layout recognition layer applies spatial analysis to identify column boundaries, reading order, table cell boundaries, figure regions, and header/footer zones. The AI-based parsing layer classifies extracted objects semantically, resolving ambiguous blocks (a text run that spans two layout columns, or a figure caption that reads syntactically like a section heading) into typed elements.
All three layers run inside Foxit’s core PDF engine, which powers 700 million+ users across 20+ years of production deployments. That engine has native awareness of PDF internal structures: content streams, XObject dictionaries, AcroForm field trees, and annotation layers. The OCR layer operates on the same internal page representation the rendering engine uses, so it handles annotated PDFs where text overlaps image regions, and form fields where the visual display and stored value diverge.
The same Structural Extraction endpoint is also Step 1 of Foxit’s PDF Translation (Trial) workflow, which signals that the extraction output is structured enough to backbone a full rewrite-and-rerender pipeline.
NVIDIA’s July 2025 NeMo Retriever research on PDF extraction showed that specialized OCR-based pipelines outperform general-purpose vision-language models on retrieval recall and throughput for complex elements including tables, charts, and infographics. VLMs produce plausible-looking output on clean documents but degrade on exactly the edge cases (multi-column scans, mixed-content pages, annotated overlays) that a specialized pipeline handles systematically.
The Full Object Map: All 12 Extractable PDF Element Types
The Structural Extraction schema v1.0.7 defines twelve element types in the type enum: title, head, paragraph, table, image, headerFooter, form, hyperlink, footnote, sidebar, annotation, and formula.
The API exposes no per-object filter parameters. The only request body fields are documentId (required) and password (optional, for protected PDFs). The engine extracts the full element graph and returns everything in one asynchronous round-trip. You filter client-side on the returned JSON. The design is correct for the workload because partial extraction would require re-running layout recognition per request, costing more compute than transmitting the full element set in a single ZIP.
The result is a ZIP archive. At minimum it contains StructureInfo.json, whose top-level analyzeResult object holds version, pages, elements, and info. Documents that contain figures or tables also produce additional binary files (image renditions and table renditions) alongside the JSON, referenced from individual elements so the JSON payload stays manageable on large documents.
Each element in the document-wide flat elements array carries its own id, type, content, region (with page and an 8-point boundingBox polygon), and score confidence value. A table element adds its cell grid. A form element adds field data. An image element points to its binary file in the ZIP. Because title, head, and paragraph elements appear in document reading order in the elements array, they chunk cleanly on semantically correct boundaries, which is what a RAG index needs to return complete, coherent passages.
Each type maps directly to a downstream use case: table feeds financial reporting pipelines, form drives automated CRM data entry, image routes to computer vision workflows or document archives, annotation builds compliance audit trails, and head combined with paragraph elements in reading order feeds RAG ingestion.
API Walkthrough: The Four-Step Async PDF Extraction Flow
There’s no synchronous path. You upload, get a task ID, poll until completion, then download the result ZIP. Every request carries two headers: client_id and client_secret (lowercase snake_case, as specified in the API spec’s security schemes). Both come from the Developer Portal’s default application. Pass them as named HTTP headers on every request and do not use Authorization: Bearer.
The four-step sequence runs as follows:
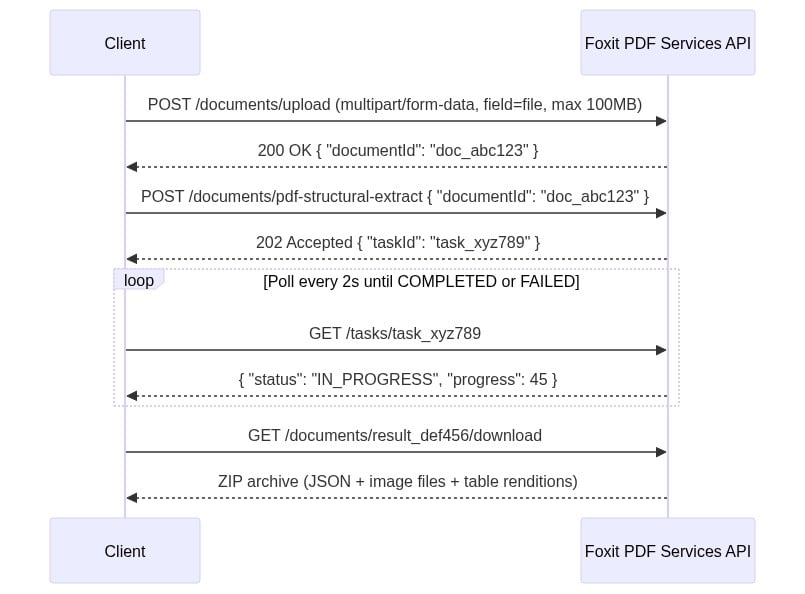
The four-step sequence diagram uses two headers on every request: client_id and client_secret. Create a free developer account at account.foxit.com/site/sign-up (no credit card required, no sales call). Once you’re in, the credentials live under the default application in the Developer Portal. Copy the Client ID and Client Secret pair and treat them like any other API secret. Pass them as named HTTP headers on every call (lowercase snake_case, not Authorization: Bearer).
Step 1: Upload the PDF to
POST /pdf-services/api/documents/uploadasmultipart/form-datawith the file under field namefile. The 100MB ceiling is enforced with a413and error codeMAX_UPLOAD_SIZE_EXCEEDED. The response body returns{ "documentId": "doc_abc123" }.Step 2: Starts extraction with
POST /pdf-services/api/documents/pdf-structural-extract, passing{ "documentId": "doc_abc123" }. Add a"password"field for protected PDFs. The response is202 Acceptedwith{ "taskId": "task_xyz789" }.Step 3: Polls
GET /pdf-services/api/tasks/{task-id}. TheTaskResponsecarriestaskId,status,progress(0-100 integer),resultDocumentId, and an optionalerrorobject. Thestatusenum values arePENDING,IN_PROGRESS,COMPLETED, andFAILED. Portal narrative copy occasionally uses “PROCESSING,” but the schema enum value isIN_PROGRESS. Match your code against the enum. Poll untilCOMPLETEDand captureresultDocumentId.Step 4: Downloads with
GET /pdf-services/api/documents/{resultDocumentId}/download, which streams the ZIP archive. The optionalfilenamequery parameter overrides the default filename.
The complete cURL sequence for all four steps:



