message gives you a status string for logging. fileExtension tells you whether you received "pdf" or "docx", which lets you construct the output filename programmatically without parsing the message string. base64FileString is the generated document. Your application decodes that value and routes the resulting bytes to storage, email delivery, a document management system, or whatever downstream step your workflow requires.
For teams evaluating the API before writing integration code, the Foxit developer portal includes a Postman collection with GenerateDocumentBase64 preconfigured. You can load the collection, paste your credentials and a test template, send the request, and confirm the response structure before writing a single line of application code. Foxit also provides SDKs for Node.js, Python, Java, C#, and PHP if you prefer a language-native integration path over raw HTTP.
Where Organizations Are Actually Using This
Five industries where the template-to-API pipeline produces direct operational value:
Insurance carriers face renewal cycles that generate thousands of policy documents each quarter. They pull policyholder data from their CRM, pass it as a JSON payload to the generation API, and produce populated renewal packets without manual assembly. Each document reflects current policy terms from the system of record, cutting the per-document preparation time from minutes of human work to milliseconds of API latency.
Healthcare providers need patient intake packets and HIPAA disclosure forms ready before each appointment. Clinics pull patient demographic and consent data from their EHR system, generate the packet at appointment scheduling time, and deliver it to the patient portal. The data source is the live EHR record, so the document always reflects current information.
Government agencies and courts produce case-related documents (orders, notices, motions) with fixed structure and variable case data. API-based generation means each document draws directly from structured court records, reducing transcription errors and producing a machine-readable audit trail that links every output document to the specific data that created it.
High-tech and SaaS companies trigger NDA and quote generation directly from their CRM or CPQ tools. A deal record in Salesforce or HubSpot becomes the JSON payload, and the generation API produces a finalized, formatted document without a manual drafting step. The document lands in the deal room minutes after the pricing conversation closes.
Education institutions generate hundreds or thousands of admission offer letters during enrollment periods. Student data from the Student Information System becomes the payload, and each letter reflects the correct program, scholarship amount, and enrollment deadline for that individual student. What a staff member would take days to produce manually runs as a scheduled batch job.
What to Evaluate When Choosing a Document Generation API
Output format coverage deserves attention before you commit to an API. Receiving both PDF and DOCX from the same endpoint matters when your workflow requires human review before a document is finalized. PDF suits direct delivery. DOCX suits draft-and-review cycles where a lawyer or editor needs to modify the generated document before it goes to signature. APIs that produce only PDF force you to finalize at generation time, which eliminates the review step entirely.
The execution model determines whether an API fits your latency requirements. Synchronous APIs return the document in the same HTTP response, which works for real-time generation triggered by a user action or a CRM event. Asynchronous APIs accept a job and require polling or a webhook to retrieve the result, which works better for batch jobs processing thousands of documents in a run. Confirm which model the API offers before you design your integration, because retrofitting from synchronous to async (or vice versa) affects how you handle errors, retries, and downstream routing. Foxit’s DocGen API is synchronous, so individual requests resolve in a single HTTP round trip.
Template portability determines your long-term maintenance cost. A template stored as a standard DOCX file is editable by anyone with Word, version-controllable in Git, and portable across environments. A template stored in a proprietary format requires the vendor’s editor for every update, and losing access to that editor means losing the ability to maintain your own document logic. Word-based templates also let business users own content changes without involving a developer.
Compliance posture matters as soon as your documents contain PII, PHI, or financial data. Confirm the provider’s certifications before sending real records through the API. SOC 2, GDPR compliance, and HIPAA certification are the relevant checks for most enterprise document workflows. A provider’s architecture (multi-tenant SaaS vs. single-tenant hosted) also affects how you address data residency requirements.
Developer onboarding cost is a real selection criterion. A free tier with immediate credential access, a working Postman collection, and SDK support for your language stack lets your team validate fit in hours. A procurement process that requires a sales conversation before you can run a test extends your evaluation cycle by weeks. Foxit’s developer plan is free, credit-card-free, and gives you dashboard access and credentials immediately, so your team can make an informed build-vs-buy decision based on a working integration rather than a demo.
Getting Started: Generate Your First Document Today
A working end-to-end generation pipeline takes under an hour to set up:
Go to account.foxit.com/site/sign-up and activate a free Developer plan. Dashboard access and credentials are immediate, with no credit card and no sales call required.
Retrieve your Client ID and Client Secret from the dashboard.
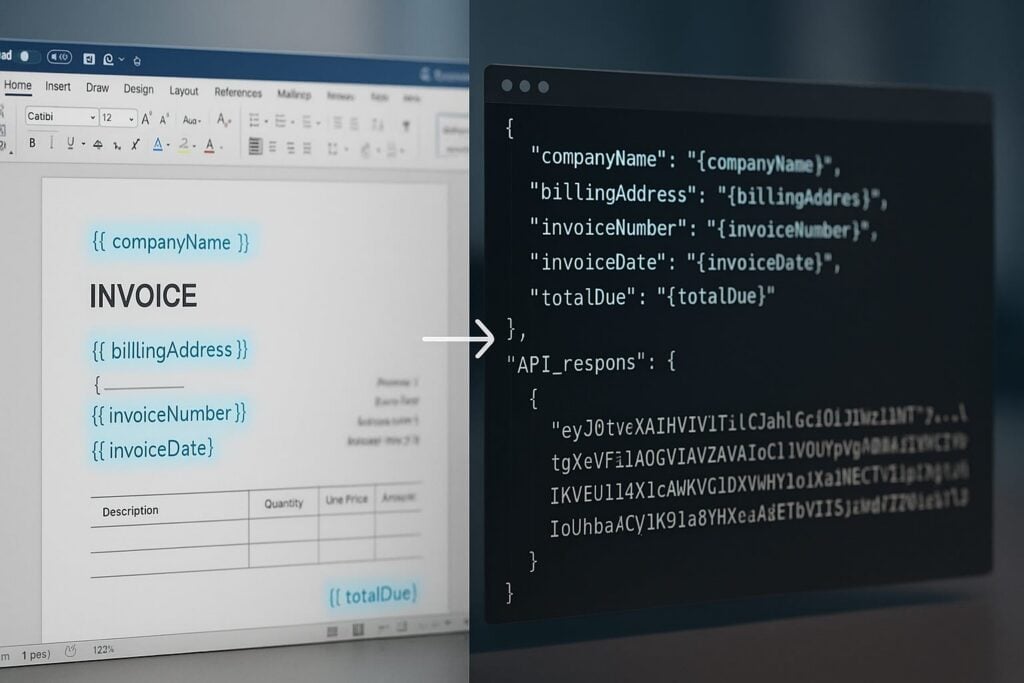
Grab a ready-to-use template, or author your own. Download invoice_simple.docx for the smallest possible smoke test, or invoice_table.docx if you want the full loop, {{ROW_NUMBER}}, and {{=SUM(ABOVE)}} round-trip. To build your own instead, open Microsoft Word, add two or three {{ tokenName }} placeholders, and save as DOCX. Base64-encode the file using base64 -i template.docx on macOS or Linux, or [Convert]::ToBase64String([IO.File]::ReadAllBytes("template.docx")) in Windows PowerShell.
Open the Postman collection linked on the Foxit API page, load the GenerateDocumentBase64 request, paste your base64-encoded template into base64FileString, and add a JSON object to documentValues with keys matching your placeholder names. Set outputFormat to "pdf" and send the request. Copy the base64FileString value from the JSON response and decode it. You now have a generated PDF.
From this point, connecting to a real data source is the only remaining step. Pull a record from your CRM, a row from your database, or a response from an upstream API, map its fields to the token names in your template, and pass the result as documentValues. That connection makes the pipeline production-ready, and every document it generates becomes a deterministic, auditable function of the data that produced it.
Activate your free Foxit Developer plan (no credit card, no sales call) and run your first document generation call in minutes at account.foxit.com/site/sign-up.